

analysis and logical design for apps
System Design Analysis of Google Drive
How do you design a system like Google Drive?
![]()
System design is one of the most important and feared aspects of software engineering. This opinion comes from my own learning experience in an associate architecture course. When I started my associate architecture course, I had a hard time understanding the idea of designing a system.
One of the main reasons was that the terms used in sof t ware architecture books are pretty hard to understand at first, and there is no clear step by step guidelines. Everybody seems to have a different approach. And of course, there is a mental block also that these topics might be tough to understand.
So, I set out to design a system based on my experience of learning architecture courses. The first one is on Google Auto Suggestion. For this one, let's design a cloud file storage service like Google drive. It's a file storage and synchronization service, enables users to store their data on a remote server.

Now those who already used Google drive know that we can upload any size of files from any device, and it can be found on our mobile, laptop, personal computer, etc. A lot of us wonder how the system handles such a massive amount of files. In this article, we will design a google drive service!!
This is by no means a comprehensive guide, rather it's an introduction to system design and a good place to start your journey to be a software architect.
★ Definition of the System
We need to clarify the goal of the system. System design is such a vast topic; if we don't narrow it down to a specific purpose, then it will become complicated to design the system, especially for newbies.
Users should be able to upload and download files/photos from any device. And the files will be synchronized in all the devices that the user is logged in.
If we consider 10Million users, 100 M requests/day in the service, the number of writing and read operations will be huge. For simplification, we're just designing the Google Drive storage. In other words, users can upload and download files, which effectively stores them in the cloud.
★ The requirements of the system
In this part, we decide on the features of the system. We can divide these requirements into two parts:
- Functional requirement:
Users should be able to upload and download files from any device. And the files will be synchronized in all the devices that the user is logged in.
These are the primary goal of the system. This is the requirement that the system has to deliver.
- Non-Functional requirement:
Now for the more critical requirements that need to be analyzed. If we don't fulfill this requirement, it might be harmful to the business plan of the project. So, let's define our NFRs:
Users can upload and download files from any device. The service should support storing a single large file up to 1 GB. Service should synchronize automatically between devices; if one file is uploaded from a device, it should be synced on all devices that the user is logged in.
★ Server-side Component Design
For newbies to system design, please remember, "If you are confused about where to start for the system design, try to start with the data flow."
Our user in this system can upload and download files. The user uploads files from the client application/browser, and the server will store them. And user can download updated files from the server. So, let's see how we handle upload and download of files for such a massive amount of users.
Upload/Download File:
From the figure, we can see that if we upload the file with full size, it will cost us storage and bandwidth. And also, latency will be increased to complete upload or download.
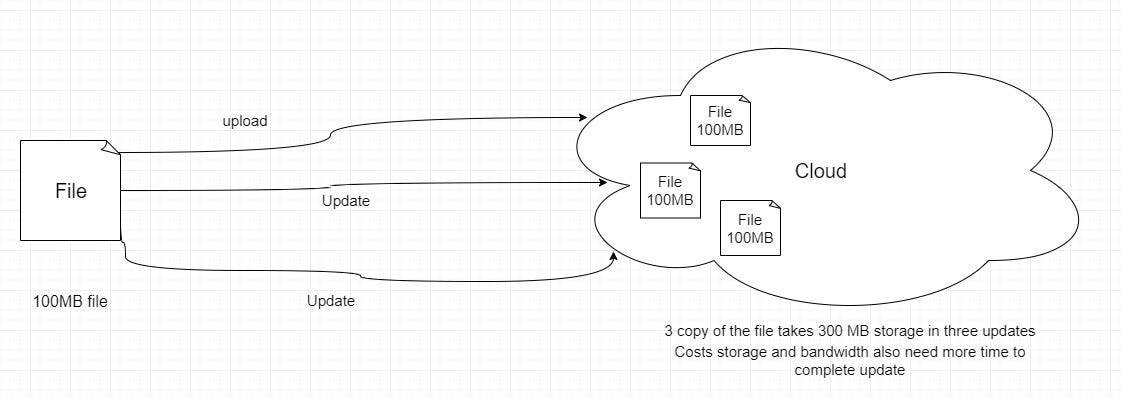
Handle file transfer efficiently:
We may divide each file into smaller chunks. Then we can modify only small pieces where data is changed, not the whole file. In case data upload failure also this strategy will help. We need to divide each file into a fixed size, say 2 MB.

Our chunk size needs to be smaller. It will help to optimize space utilization, and network bandwidth is another considering factor while making the decision. Metadata should include the record of each file's chunk information.
As we have this article for practice, so we may assume that files need to be stored in small chunks of 2 MB. We will get benefits in case of retry operation also for smaller pieces of a file if a process is failed. If a file is not uploaded, then only the failing chunk will be retried.
Less amount of data transfer between clients and cloud storage will help us achieve a better response time. Instead of transmitting the entire file, we can send only the modified chunks of the files.
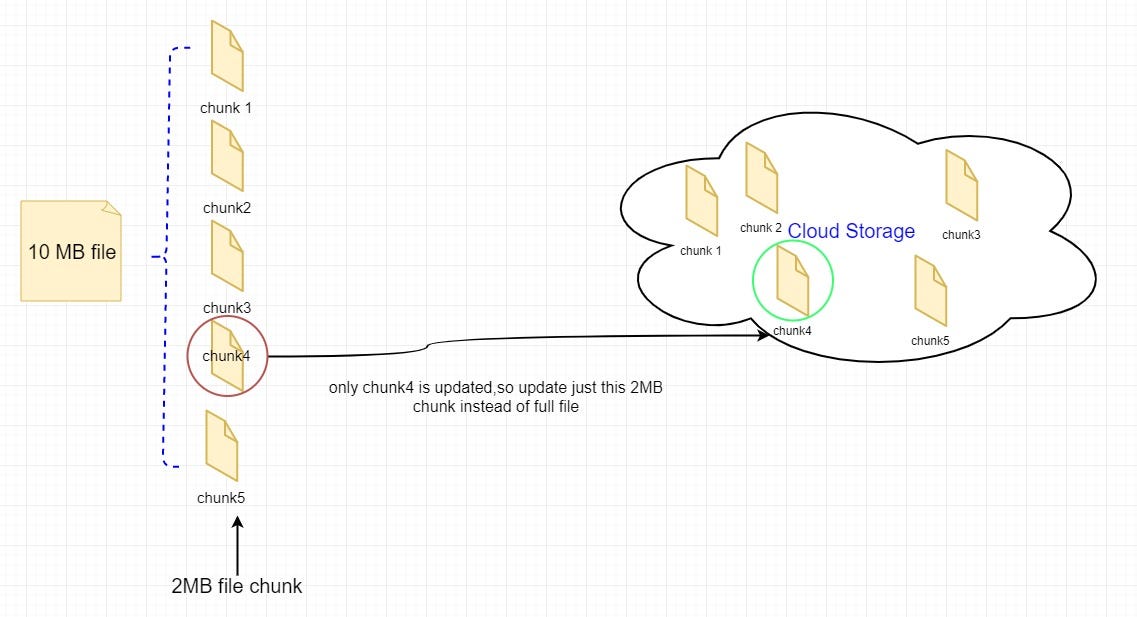
In that case, the updated part of the file will be transmitted. We will be dividing files into 2MB chunks and transfer the modified portion of files only, as you can see from the figure.
From the figure above, you may see, instead of updating the whole 10 MB file, we can just update the modified 2MB potion of the file. It will decrease bandwidth consumption and cloud storage for the user. Most importantly, the response time will be faster.
What will happen when the client is offline?
A client component, Watcher, will observe client-side folders. If any change occurs by the user, it will notify the Index Controller(another client component) about the action of the user. It will also monitor if any change is happening on other clients(devices), which are broadcasted by the Notification server.
When the Metadata service receives an update/upload request, it needs to check with the metadata DB for consistency and then proceed with the update. After that, a notification will be sent to all subscribed devices to report the file update.
Metadata Database:
We need a database that is responsible for keeping information about files, users, etc. It can be a relational database like MySQL or NoSQL like MongoDB. We need to save data like chunks, files, user information, etc. in the Database.
As we all know, we have to choose between two types of Database, SQL or NoSQL. Whatever we choose, we need to ensure data consistency.
Using a SQL database may give us the benefit of the implementation of the synchronization as they support ACID properties.
NoSQL databases do not support ACID properties. But they provide support for scalability and performance. So, we need to provide support for ACID properties programmatically in the logic of our Metadata server for this type of Database.
Synchronization:
Now the client updates a file from a device; there needs to be a component that process updates and applies the change to other devices. It needs to sync the client's local Database and remote Metadata DB. MetaData server can perform the job to manage metadata and synchronize the user's files.
Message Queue:
Now think about it; such a huge amount of users are uploading files simultaneously, how the server can handle such a large number of requests. To be able to handle such a huge amount of requests, we may use a message queue between client and server.
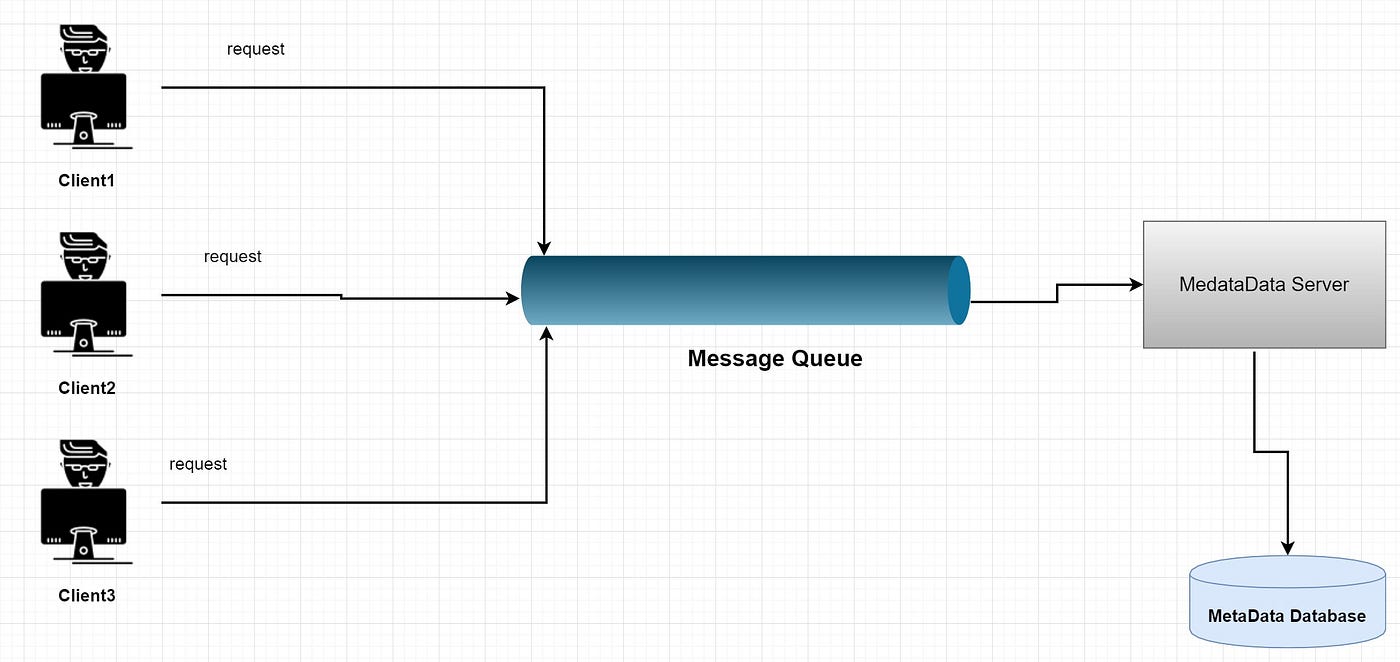
The message queue provides temporary message storage when the destination program is busy or not connected. It provides an asynchronous communications protocol. It is a system that puts a message onto a queue and does not require an immediate response to continue processing. RabbitMQ, Apache Kafka, etc. are some of the examples of the messaging queue.
In case of a message queue, messages will be deleted from the queue once received by a client. So, we need to create several Response Queues for each subscribed device of the client.
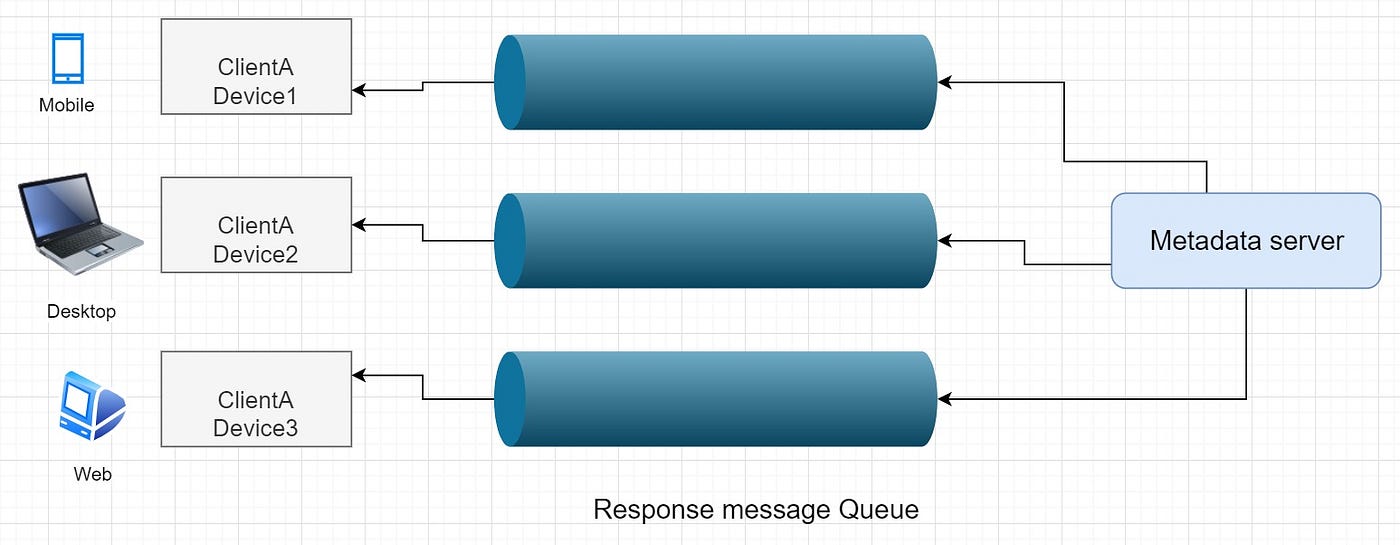
For a massive amount of users, we need a scalable message Queue that supports asynchronous message-based communication between client and synchronization service. The service should be able to efficiently store any number of messages in a highly available, reliable, and scalable queue. Example: apache Kafka, rabbitMQ, etc.
Cloud Storage:
Nowadays, there are many platforms and operating systems like smartphones, laptops, personal computers, etc. They provide mobile access from any place at any time.
If you keep files in the local storage of your laptop and you are going out but want to use it on your mobile phone, how can you get the data? That's why we need cloud storage as a solution.
It stores files(chunks) uploaded by the users. Clients can interact with the storage through File Processing Server to send and receive objects from it. It holds only the files; Metadata DB keeps the data of the chunk size and numbers of a file.
File processing Workflow:
Client A uploads chunk to cloud storage. Client A updates metadata and commits changes in MetadataDB using the Metadata server. The client gets confirmation, and notifications are sent to other devices of the same user. Other devices receive metadata changes and download updated chunks from cloud storage.
★Scalability
We need to partition the metadata database so that we can store information about 1 million users and billions of files/chunks. We can partition data to distribute the read-write request on servers.
MetaData Partitioning:
i) We can store file-chunks in partitions based on the first letter of the File Path. For example, we keep all the files starting with the letter 'A' in one partition and those beginning with the letter 'B' into another partition and so on. This is called range-based partitioning. Less frequently occurring letters like 'Z' or 'Y,' we can combine them into one partition.
The main problem is that some letters are common in case of a starting letter. For example, if we put all files starting with the letter 'A' into a DB partition, and we have too many files that begin with the letter 'A,' so that that we cannot fit them into one DB partition. In such cases, this approach will have a disadvantage.
ii) We may also partition based on the hash of the 'fileId' of the file. Our hash function will randomly generate a server number, and we will store the file in that server. But we might need to ask all the servers to find a suggested list and merge them together to get the result. So, response time latency might be increased.
If we use this approach, it can still lead to overloaded partitions, which can be solved by using Consistent Hashing.
Caching:
As we know, caching is a common technique for performance. This is very helpful to lower the latency. The server may check the cache server before hitting the Database to see if the search list is already in the cache. We can't have all the data in the cache; it's too costly.
When the cache is full, and we need to replace a chunk with a newer chunk. Least Recently Used (LRU) can be used for this system. In this approach, the least recently used chunk is removed from the cache first.
★Security:
In a file-sharing service, the privacy and security of user data are essential. To handle this, we can store the permissions of each file in the metadata database to give perm what files are visible or modifiable by which user.
★ Client-Side:
The client application(web or mobile) transfers all files that users upload in cloud storage. The application will upload, download, or modify files to cloud storage. A client can update metadata like rename file name, edit a file, etc.
The client app features include upload, download files. As mentioned above, we will divide each file into smaller chunks of 2MB so that we transfer only the modified chunks, not the whole file.
In case any conflict arises due to the offline status of the user, the app needs to handle it. Now, we can keep a local copy of metadata on the client-side to enable us to do offline updates.
The client application needs to detect if any file is changed in the client-side folder. We may have a component, Watcher. It will check if any file changes occurred on the client-side.
★How would clients know change is done in cloud storage?
The client can periodically check with the server if there is any change, which is a manual strategy. But if the client frequently checks server changes, it will be pressure for the server, keep servers busy.
We may use HTTP Long polling technique instead. In this technique, the server does not immediately respond to client requests. Instead of sending an empty response, the server keeps the request open. Once new information is ready, then the server sends a response to the client.
We can divide client application into these parts:
✓ Local Database will keep track of all the files, chunks, directory path, etc. in the client system.
✓ The Chunk Controller will split files into smaller pieces. It will also perform the duty to reconstruct the full file from its chunks. And this part will help to determine only the latest modified chunk of a file. And only modified chunks of a file will be sent to the server, which will save bandwidth and server computation time.
✓ The Watcher will observe client-side folders, and if any change occurs by the user, it will notify the Index Controller about the action of the user. It will also monitor if any change is happening on other clients(devices), which are broadcasted by Synchronization service.
✓ The Index controller will process events received from the Watcher and update the local Database about modified file-chunk information. It will communicate with the Metadata service to transfer changes to other devices and update the metadata database. This request will be sent to the metadata service via the message request queue.
Below is the full diagram of the system:
★Conclusion:
In this system, we did not consider the UI part. The history of the updates and offline editing was also not considered in the system. The mobile client could sync on-demand to save the user's bandwidth and space. Here we did not use another server for synchronization. The Metadata Server is performing that task.
We decided to divide files into smaller chunks to save storage, bandwidth usage, and also decrease latency. We added the Loadbalancer to distribute incoming requests equally among backend servers. If a server is dead, LB will stop sending any request to it.
In cloud architecture, the privacy and security of user data are essential. We can store the permissions of each file in the metadata DB to check which files are visible or modifiable by which user.
The first part of this series is on Google Auto Suggestion. And for steps to design a system check this link:
Reference: Grokking the System Design course. And for video reference you may check this link. Thank you for reading the article. Have a good day 🙂
analysis and logical design for apps
Source: https://towardsdatascience.com/system-design-analysis-of-google-drive-ca3408f22ed3
Posted by: chavisiont1981.blogspot.com
0 Response to "analysis and logical design for apps"
Post a Comment